Pourquoi Internet repose aujourd’hui sur un petit nombre d’acteurs - et pourquoi c’est un problème
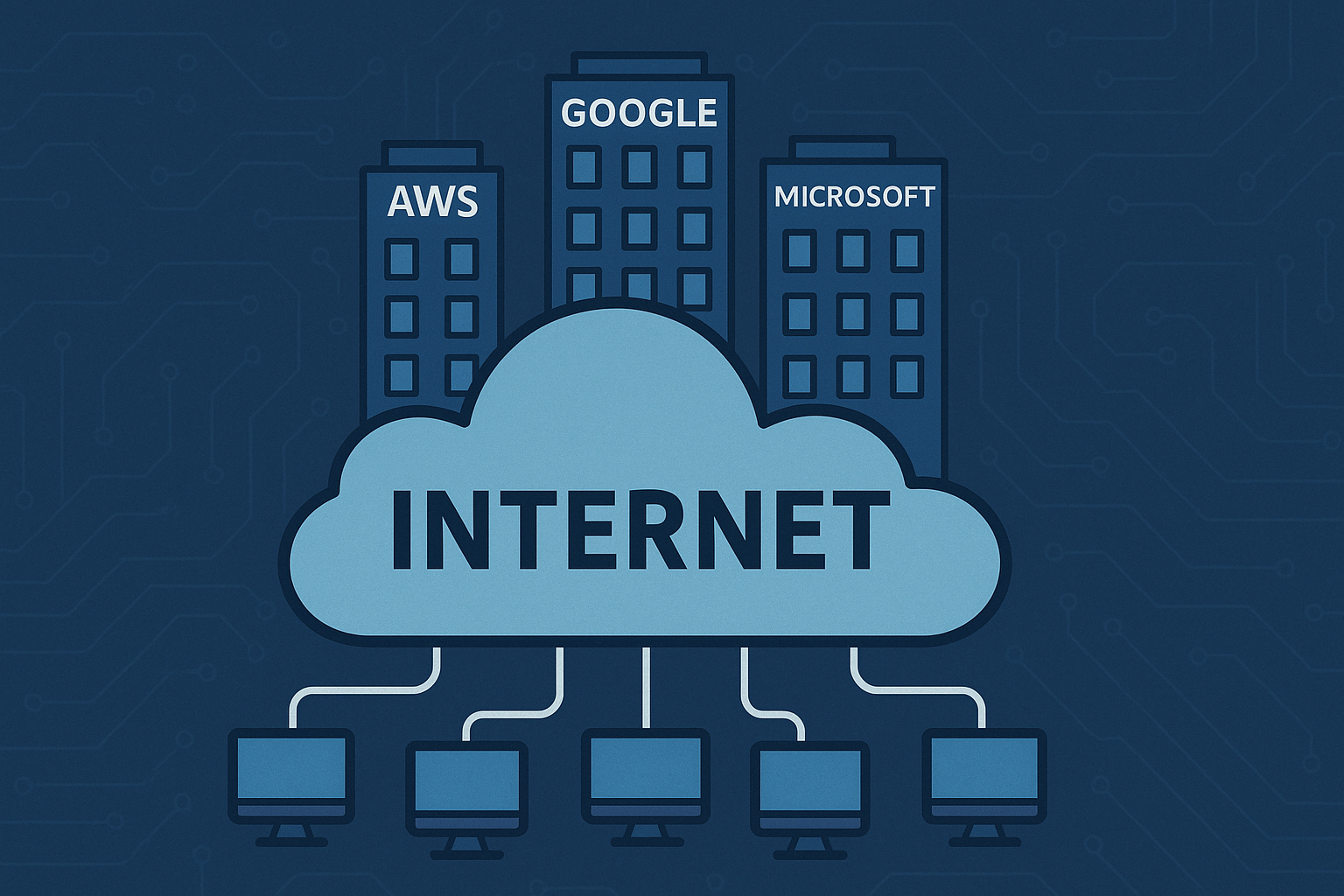
L’internet “moderne” - tel qu’il fonctionne aujourd’hui - s’appuie massivement sur une poignée de fournisseurs de cloud. Ces géants proposent des services de compute, stockage, DNS, CDN, authentification, edge-routing, offrant aux entreprises et aux services en ligne une solution clé-en-main et ultra-scalable.
Cet état de fait s’explique par des économies d’échelle considérables : construire et maintenir des data centers, assurer la connectivité globale, gérer l’infrastructure réseau et de stockage, tout cela représente un investissement colossal - investissement que seuls les hyperscalers peuvent supporter sur le long terme.
Mais cette concentration introduit un risque systémique : quand un gros acteur subit une panne, une grande partie d’internet peut être affectée. En d’autres termes, ces fournisseurs incarnent des “single points of failure” pour des pans entiers du web - ce qui va à l’encontre de l’esprit originel d’un internet distribué.
Les pannes récentes montrent la fragilité du modèle centralisé
L’incident d’octobre 2025 sur AWS - lié à une défaillance DNS interne autour de services critiques - a provoqué des interruptions massives de services dans le monde entier, y compris des plateformes crypto, SaaS, e-commerce, etc.
En novembre 2025, une panne globale sur le réseau edge / proxy d’un grand CDN a entraîné des erreurs 5xx massifs pour des milliers de sites, rendant inaccessible une part importante du web.
Au-delà des pannes techniques, le modèle centralisé rend l’infrastructure vulnérable à des décisions “humaines” : changements de configuration erronés, mises à jour, erreurs dans les pipelines de déploiement, ou encore pression réglementaire ou géopolitique dans certains pays.
Ces événements soulignent une réalité : même des services bâtis sur des principes de décentralisation (blockchain, crypto) s’appuient souvent, en sous-couche, sur des infrastructures centralisées - ce qui les rend vulnérables aux mêmes défauts.
Vers la décentralisation réelle : architectures alternatives et concepts fondamentaux
Reconnaître la fragilité du modèle actuel pousse à repenser l’infrastructure d’Internet. Plusieurs paradigmes techniques émergent pour répondre aux besoins de résilience, souveraineté, disponibilité, résistance à la censure.
Centralisé vs décentralisé : les fondements d’un débat d’architecture
Dans une architecture centralisée, l’essentiel du traitement, du stockage ou de l’authentification est concentré sur un ou quelques serveurs maîtres. Cela simplifie la gestion, mais crée un point de contrôle unique.
Inversement, une architecture décentralisée distribue ces responsabilités sur de nombreuses machines — idéalement indépendantes — réduisant les risques de panne globale, de censure ou de blocage.
Dans ce cadre, des projets et méthodologies tels que :
- Le cloud décentralisé (via des réseaux de nœuds indépendants, coordonnés par des mécanismes de consensus, blockchain ou autres)
- L’edge / fog / dew computing, déplaçant le traitement plus proche de l’utilisateur ou des objets connectés, plutôt que de tout concentrer dans des data centers centralisés
- Des systèmes de stockage / distribution de contenu pair-à-pair, comme les solutions promues par le mouvement Web3, qui évitent de dépendre d’un seul fournisseur de CDN ou de stockage
Ces approches permettent une redécentralisation d’Internet — c’est-à-dire un retour à une architecture plus fidèle à sa philosophie d’origine, fondée sur le réseau de réseaux, ouverte et distribuée.
Défis techniques et limites des modèles décentralisés - mais des pistes concrètes
La décentralisation ne vient pas sans défis. Parmi les principaux obstacles :
- Scalabilité : répartir des charges lourdes (compute, stockage, trafic) sur de nombreux nœuds hétérogènes peut compliquer la performance, la latence, la cohérence data
- Coordination et orchestration : la gestion des ressources, la découverte de services, le routing — dans un environnement décentralisé — demandent des protocoles robustes (souvent blockchain, ou des plans de contrôle distribués)
- Adoption et compatibilité : beaucoup d’applications existantes supposent des services centralisés (auth, DNS, CDN, stockage). Migrer vers des modèles décentralisés nécessite souvent de réarchitecturer des pans entiers
- Économie & incitations : pour qu’un réseau décentralisé soit viable à grande échelle, il faut un modèle économique durable (rétribution des nœuds, garantie de disponibilité, SLA, etc.).
Cependant, ces défis ne sont pas insurmontables - les projets récents et les publications académiques montrent que des architectures hybrides ou purement distribuées deviennent techniquement crédibles.
Pourquoi c’est stratégique (pour les entreprises, les États, les utilisateurs) ?
Résilience & souveraineté
Dépendre d’un seul ou de quelques fournisseurs cloud signifie confier le destin de ses services à ces acteurs — et potentiellement à leurs contraintes juridiques, géopolitiques, financières ou techniques.
Dans un modèle décentralisé, les services sont répartis, ce qui réduit le risque qu’un incident ou une décision unilatérale mette à genoux un pan entier de l’écosystème.
Neutralité & liberté d’accès
La décentralisation rend l’accès au web moins sujet à la censure, aux blocages géographiques, ou à la surveillance massive. Les utilisateurs conservent plus de contrôle sur leurs données.
Elle s’aligne avec les valeurs originelles d’Internet : open-source, interopérabilité, résilience.
Innovation et indépendance
Un Internet décentralisé offre un terrain fertile pour des services résilients, modulables, plus proches des utilisateurs ou de leurs devices (edge, IoT, fog, dew computing).
Les barrières d’entrée sont potentiellement plus faibles : on peut imaginer un modèle “cloud mondial communautaire”, où chacun (entreprise ou particulier) peut contribuer au backbone d’Internet.
Contexte technique détaillé des pannes (juillet à novembre 2025)
Cloudflare - Panne mondiale Bot Management / ClickHouse (18 novembre 2025)
Cloudflare génère toutes les 5 minutes un fichier de “features” utilisé par son Bot Management. Une modification des permissions sur ClickHouse a commencé à renvoyer des résultats dupliqués, dépassant la limite maximale de features supportée par les proxies edge. Chaque déploiement d’un fichier “corrompu” faisait crash les nœuds, générant des erreurs 5xx planétaires. Cloudflare a stoppé la propagation, injecté un fichier sain et redéployé la configuration.
Azure - Panne Azure Front Door (29 octobre 2025)
Une configuration client, générée par deux versions incompatibles de la control plane AFD, a produit une metadata corrompue. Le pipeline de déploiement a validé cette configuration sans détecter l’erreur. Une fois propagée, cette metadata a fait crash la data plane sur les edge POPs, y compris le service DNS interne d’AFD. Microsoft a corrigé la configuration, poussé une nouvelle LKG (Last Known Good) et renforcé les étapes de validation.
AWS - Panne DNS interne / DynamoDB (19–20 octobre 2025)
Une mise à jour interne de l’API DynamoDB a généré un enregistrement DNS vide dans l’infrastructure interne d’AWS, rendant certains endpoints impossibles à résoudre. Les services dépendant de DynamoDB pour leur métadonnées - EC2, Lambda, IAM, STS, API Gateway - sont entrés en “retry storm”, saturant les plans de contrôle. L’impact s’est propagé à l’échelle mondiale, touchant des milliers de services tiers. AWS a rerouté la résolution vers des resolvers sains, purgé les caches DNS et neutralisé l’automatisation fautive.
Cloudflare <> AWS - Congestion de peering (21 août 2025)
Un seul client AWS us-east-1 a saturé les Private Network Interconnects (PNI) Cloudflare <> AWS en envoyant des volumes massifs vers des objets déjà en cache. En réponse, AWS a retiré plusieurs préfixes BGP, reroutant le trafic vers des liens déjà proches de la saturation, aggravant l’instabilité. Les équipes ont appliqué un rate-limiting ciblé et redistribué les routes.
Vers un internet plus robuste, plus libre, plus résilient
L’histoire des pannes récentes - qu’elles surviennent sur un géant du cloud, un CDN, ou un backbone réseau - rappelle que l’infrastructure actuelle d’Internet repose sur une centralisation excessive.
Pour que l’esprit initial d’Internet (un réseau distribué, ouvert et résilient) survive à l’échelle 2025 et au-delà, il paraît essentiel d’embrasser les modèles distribués / décentralisés, non seulement sur la couche applicative (crypto, Web3), mais jusqu’à la couche infrastructure.
Des architectures comme le cloud décentralisé, les réseaux DePIN, le fog/edge computing, ou encore le pair-à-pair pour le stockage et la distribution, offrent aujourd’hui des alternatives crédibles. Leur adoption progressive, combinée à des approches hybrides (mix centralisé + distribué), pourrait être la voie pour un internet plus robuste, décentralisé dans les faits - et pas seulement dans le discours.
Sources






